
Just about every article you see in Forbes or Wired about Artificial Intelligence bellows market compound annual growth rates of 40% or more during the next five years in terms of billions of dollars. The U.S. Bureau of Labor Statistics forecasts that 11.5 million new jobs will be created by the year 2026. It’s easy to get excited about the hype, and you may have noticed how often the term “machine learning” or “AI” is being spoken about on earnings conference calls by many public companies recently. [In this article, I tend to interchange AI with machine learning (ML). ML is a subset of AI, and Deep Learning is another subset of AI.] It seems our affection for buzzwords continues to grow for the attention deficit technologists. During my work with various organizations in the healthcare industry, one persistent theme is at the forefront – how do we position ourselves for success using AI? Healthcare providers have little room for experimentation or hypothesis testing when they are dealing with human lives where mistakes are life and death situations.
Gartner, IDC, and other research firms have estimated failure rates of AI projects from 80%-85% in terms of delivering value – mostly as CIOs see it. We may be asking the wrong people. Like many technology disruptions quite often, we have too much attention on the technology itself and not on the use cases it may be able to solve. There is a multitude of vendors and startups up and down the technology stack ready to demonstrate why their tool or insight capability is better than what we’ve spent years implementing. Many firms are still grappling with data governance and core enterprise data warehousing – data liquidity is still an elusive goal. The business leaders owning the profit & loss for the enterprise are the ones who need to step up and invest in learning how to express problems in terms that data scientists can understand. In a business scenario where you can provide rules that provide you a straightforward yes or no answer, or you can calculate an exact amount, then you don’t need machine learning. If you can obtain a specific number based on a set of conditions, then conventional computer programming is all you need.
How about Genuine Intelligence instead of Artificial?
We need to think about machine learning less like a computer scientist and more like a human being. Machine learning is not a new way to solve familiar problems. We need to think about issues where we thought computers couldn’t help us. We enter a world of predictions and probabilities, not exact answers.
How to Avoid an 85% Failure Rate with Machine Learning Projects
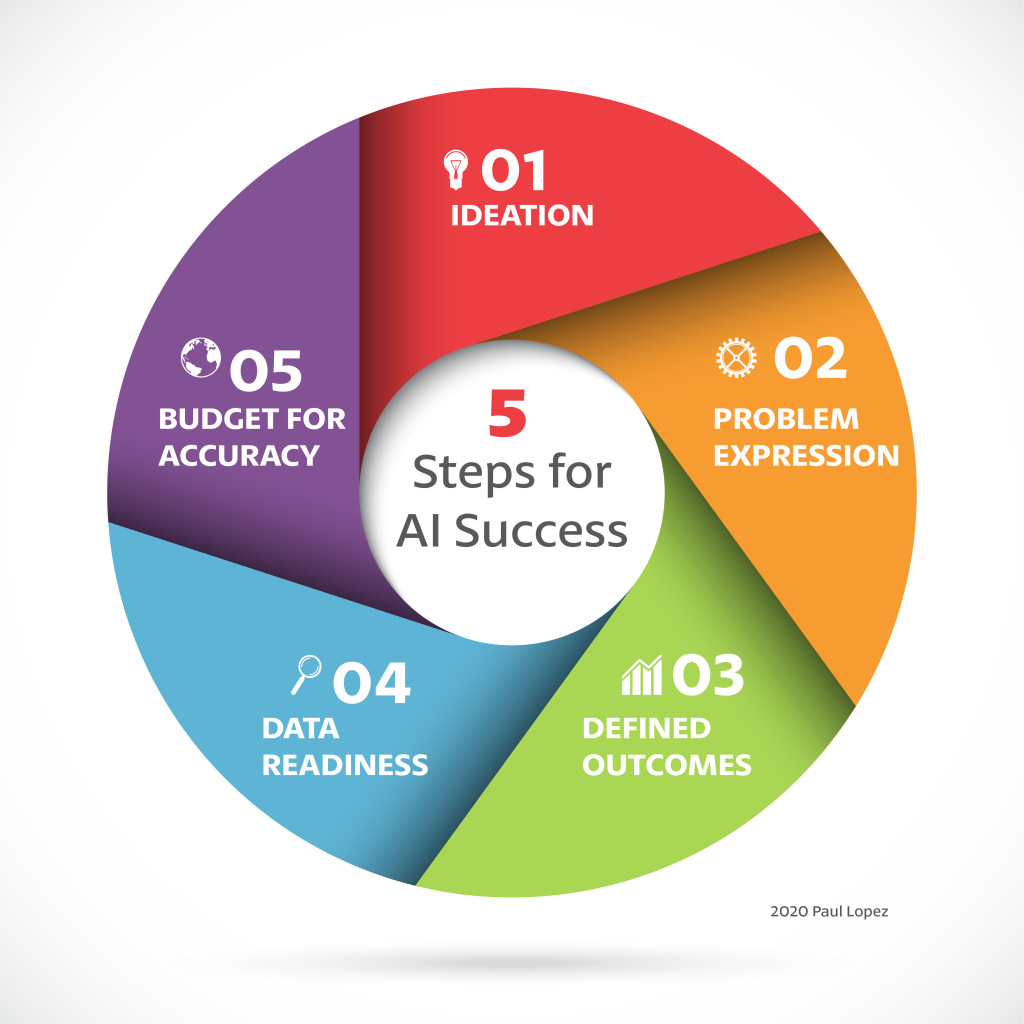
Step One: Ideation
This the first step – Ideation. It’s about finding out about things where Google or Alexa are unable to help. Spending time with thoughtful mindfulness about your business and asking yourself what are some unknowns you wish you could know? As humans, we have to own the “Why.” We can be assisted with AI to help with the What, When, and Where.
Humans own the Why
All Machine learning can do is take some existing data, analyze it to identify patterns, and then use the results to make better predictions about new data you send to a model. We shouldn’t make it more complicated than that. Of course, there are many techniques and strategies associated with ML and Deep Learning that deserve future articles. As a business leader, consider how applied machine learning can make your intuition and business judgment more data-driven.
Identify the types of problems machine learning can solve.
Step Two: Problem Expression
Problem expression is the second step in your AI journey. It is the most critical step in the process.
Think of problem expressions in the following groups:
- Assignment – ML is particularly useful at identifying what something is (classification) or the extent to which items are connected (regression)
- Grouping – determining correlations and subsets of data (clustering)
- Generation – creating images or text based on inputs (generation)
- Forecasting – predicting changes in time series data (sequencing)
It is essential to determine if your AI project falls within the definition of assignment, grouping, generation, or forecasting. If the problem expression falls outside of the description above, then machine learning is not a useful candidate. It may still be a viable problem to address with other means. You must be able to express the problem clearly and concisely, or the AI team will struggle to choose and implement the appropriate machine learning techniques.
Step Three: Defined Outcomes
Can you define a successful outcome?
In the agile world, there is a concept called “Definition of Done.” The practice creates closure of sprints by having written acceptance criteria for designed features (collection of user stories). For an AI project, if you are converting an existing manual process, you need to know the current workflow performance in terms of accuracy and speed. Otherwise, how will you know your machine learning model is successful? Defining outcomes is the third step.
Step Four: Data Readiness
Data is the oxygen of AI/ML; without it, nothing happens. Datasets are the fuel that ignites learning in ML models. You must have sufficient data to train and test the system. When choosing problem domains, the areas where you have the most significant supply of high-quality data are the right places to start. There are many considerations of data, including its governance, provenance, lineage, protection, and security. Still, when we think of data readiness, we mean suitability of data across these five well-known characteristics:
- Balanced – Much of the public data available today contain bias. There is an intense attention to perpetuating the problems with prejudice and inequality in our society. A biased data set will produce a biased or one-sided model. The topic of dataset bias deserves more unpacking in a later post. If your data has significantly more samples of one type of output than another, your model will exhibit bias.
- Comprehensive – Your dataset must include all variables needed for assignment or grouping exercises. Unwarranted correlations can arise from data with missing variables.
- Representative – The data cannot be different from what you will use to feed your model in a live production environment. Data mismatches can be frustrating to data scientists because even though they can show a high degree of accuracy during training, the results are inadequate if the data differs significantly.
- Inclusive – It is essential to include those corner cases that may be rare occurrences in training data. A system does not generalize effectively without diverse data. The model may wrongly correlate or misclassify results in certain situations.
- Sufficiency – Typically, for more complex problems, you will require data exhibiting more occurrences or examples for each label. Studies have shown useful results after 1,000 cases. Forecasting systems typically require twice the duration of the time horizon in the base period.
Step Five: Budget for Model Accuracy
The time it takes to realize the benefits of artificial intelligence is less specific than for traditional software development. Timescales can vary according to the problem types, subject domain, and especially data availability. A Model is the result of a machine learning process. It isn’t a product or service; it’s a capability and one that involves proper care and feeding to create lasting competitive value. It is difficult to estimate how long it takes to develop a production-ready ML model. There are multiple cycles of training, experimentation with data combinations, and tuning of hyperparameters that define how the solution learns. It may only take a few days to develop a prototype with 50% accuracy. It could take weeks to obtain 80% accuracy and months to achieve 95% accuracy. The time horizon is non-linear and more logarithmic. It is best to develop a budget based on ML accuracy desired. There are other factors to consider, including the complexity of the domain, compliance, ethical concerns, availability of high-quality data, and utilization of in-house or external development teams.
Conclusion
AI is a vast collection of technologies that creates a framework of capabilities. These capabilities enable machines to exhibit human-like levels of intelligence. As the model creators, we need to spend time brainstorming with stakeholders as part of ideation. To realize AI’s potential for value creation, you must have clear and concise problem statements, each with desired outcomes defined. High quality and sufficient training and test data have to be provisioned or sourced. Then a viable business plan with realistic timelines will determine a budget. Carefully scoping the initial projects applying genuine intelligence from a well-thought-through starting point will improve your success rate.