
You hear how much artificial intelligence is saturating the cloud technology landscape with promises of human-like interactions, communications, learning, and, shall I dare to say, thinking? Now that data scientists and machine learning engineers have access to better toolchains, development platforms, and software patterns, we now turn our attention to production deployments. For machine learning to continue as a leading innovation catalyst, it has to learn efficiently at scale and integrate with cloud-native technologies. Cloud-native refers to infrastructure as API-driven, container-friendly, serverless, and open-source.
Why Machine Learning Applications are hard to run in Production
Historically, machine learning technical stacks were static, and when you tried to move them from a laptop to a cloud environment, you had to re-architect them. The various tasks of data preparation, training, tuning, and inference require different processing power levels. ML developers need compute environments with some granularity.
Teams of ML engineers want to share environments for concurrent projects. Rather than stand up dedicated hardware to support ML training’s surging nature, a multitenancy cluster allows shared access to compute without waiting for manual provisioning. Being able to create infrastructure using APIs accelerates DevOps for machine learning pipelines with automatic scaling to create ML-Ops specifically for data scientists.
Machine Learning code is tiny compared to the platform services required to run and serve a model in production. When you consider configuration, data collection, machine resource management, workflow, serving infrastructure, and monitoring, it’s no surprise production deployments can take weeks or months to complete.
Of the several ML platforms services, one stands out – Kubeflow.
Kubeflow is a scalable, composable, and portable ML stack built to run on Kubernetes. As an open-source project, Kubeflow is a full-fledged member of the leading cloud-native technologies designed to make machine learning algorithm training, and prediction, more convenient to manage on production-grade Kubernetes clusters. Kubeflow relies on Tensorflow, a leading software library that uses geometric tensor structures to express linear relations between data. It performs this by abstracting away the hardware platform where stateful dataflow graphs can run on CPUs, GPUs, or TPUs (tensor processing units).
Kubeflow simplifies production deployment of machine learning capabilities
Machine learning applications have a different footprint than web or mobile apps. For example, during the training phase, compute resources are extremely important. During the inference phase, the application needs to be fast and lightweight.
Kubeflow provides the following benefits:
Portability – Tensorflow models become modular microservices that run in containers anywhere and on any Kubernetes cluster
Scalability – machine learning models gain access to a vast range of computing power from CPU to TPU where you can dynamically increase or decrease resources.
Composability – choosing what is right for your project, mixing and matching components making up each stage in the lifecycle, and incorporating ML-specific libraries and frameworks without impacting deployment. The diagram below shows the most recent block components of Kubeflow and visually explains what is meant by composability. There are so many options to choose from, especially for pipelines and model serving. The machine learning developer can be rest assured their code is intelligently managed by Kubeflow to operate over a variety of production scenarios. One can make an entire career just from specializing in Kubernetes and data scientists can learn as much as they want to without having to become an expert. It is hard to divert attention between two such innovative domains.
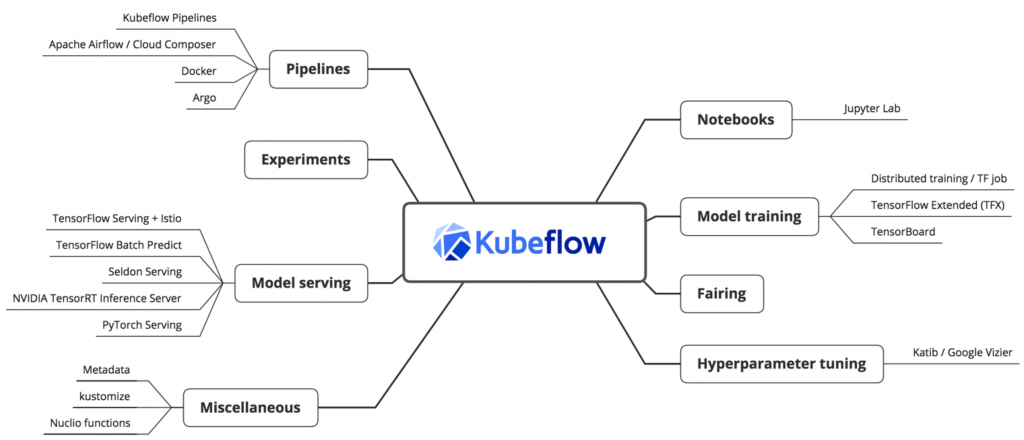
Google created Kubeflow as a way to open-source TensorFlow Extended (TFX) and Version 1.0 was released on March 2, 2020. It has grown to become a diverse architecture capable of running entire machine learning pipelines in multi-cloud frameworks or within complex enterprise datacenters. You can install Kubeflow to Google Kubernetes Engine (GKE) by giving your deployment a name, a zone, a project ID, and press Enter. That’s it! The system provisions all the necessary K8s resources automatically. You can run Kubeflow on AWS and Azure also, but as you can imagine, it takes a few more steps.
Tensorflow models use Kubeflow to enable them to execute as a cloud-native microservice on Kubernetes.
Once installed, you can train your models, build pipelines, visualize them with TensorBoard, serve models, and use JupyterHub to manage everything. A happy data scientist now knows what it’s like to live in the DevOps equivalent world of ML-Ops. You can run ML applications in the smallest of form factors – in smartphones, UX Javascript, drones, Raspberry Pi, and IoT edge electronics like Arduino.
Some fascinating components of Kubeflow include KFServing, Istio, and Katib. KFServing is built on the serverless app framework, KNative, and supports serving models based not only on Tensorflow but also on PyTorch, Scikit-Learn, ONNX, and XGBoost. Istio is an open service mesh platform to connect, observe, secure, and control microservices. Google, IBM, and Lyft created it. Kubeflow 1.0 requires Istio for AuthN and AuthZ support. Another component, Katib, is a K8s-native hyperparameter service inspired by Google Vizier. It is considered a beta version in Kubeflow 1.0. It offers extensible algorithms and has simple integrations with other Kubeflow components.
The Cluster is the Computer
Kubeflow is to ML developers what Docker is to software developers. Guess what? The old maxim “it works on my development machine but not on the production host” also applies to ML code. I hope data scientists take the time to learn Kubeflow and become conversant with the high-level dimensions of Kubernetes. Understanding how creators build these open-source platforms will stir the creativity of data scientists and enable them to bring valuable solutions to complex problems.